¶ pacemaker管理员手册
¶ 2.1 介绍
¶ 2.1.1 本文件的适用范围
本文档的目的是帮助系统管理员学习如何管理Pacemaker集群。
系统管理员可能会对Pacemaker文档集的其他部分感兴趣,如Clusters from Scratch(从零开始的集群)和Pacemaker Explained(关于集群配置的详尽参考)。
多个高级工具(包括命令行和GUI)可以用来简化集群管理。然而,本文件的重点是Pacemaker本身所提供的低级命令行工具。这些概念适用于高级工具,尽管语法有所不同。
¶ 2.1.2 什么是pacemaker?
Pacemaker是一个高可用性的集群资源管理器–在一组主机(节点集群)上运行的软件,以保持所需服务(资源)的完整性并尽量减少停机时间。它是由ClusterLabs社区维护的。
Pacemaker的主要功能包括:
-
节点和服务级故障的检测和恢复
-
通过对有问题的节点设置栅栏来确保数据的完整性
-
每个集群支持一个或多个节点
-
支持多种资源接口标准(任何可以用脚本编写的东西都可以被集群化)
-
支持(但不要求)共享存储
-
支持几乎所有的冗余配置(主动/被动,N+1等)。
-
自动复制的配置,可以从任何节点进行更新
-
能够指定服务之间的集群范围的关系,如订购、同地和反同地等
-
支持高级服务类型,如克隆(需要在多个节点上活动的服务)、可推广的克隆(可在两种角色中的一种运行的克隆)和容器化服务
-
统一的、可编写脚本的集群管理工具
栅栏,也被称为STONITH(Shoot The Other Node In The Head的缩写),是确保一个节点不可能运行服务的能力。这是通过栅栏设备实现的,如切断目标电源的智能电源开关,或切断目标对本地网络访问的智能网络开关。
Pacemaker将栅栏设备作为一种特殊的资源类别。
如果没有围栏,集群就不能安全地从某些故障条件下恢复,例如一个无响应的节点。
集群架构
在高层次上,一个集群可以被看作是有这些部分(它们在一起通常被称为集群堆栈):
-
Resources: 这些是集群存在的原因–需要保持高可用性的服务。
-
Resource agents: 这些是脚本或操作系统组件,在给定一组资源参数的情况下,启动、停止和监控资源。它们在Pacemaker和管理服务之间提供了一个统一的接口。
-
Fence agents: 这些是执行节点围栏行动的脚本,给定一个目标和围栏设备参数。
-
Cluster membership layer:: 这个组件提供关于集群的可靠的信息传递、成员和法定人数信息。目前,Pacemaker支持Corosync作为这个层。
-
Cluster resource manager: Pacemaker提供了处理集群中发生的事件并作出反应的大脑。这些事件可能包括节点加入或离开集群;由故障、维护或计划活动引起的资源事件;以及其他管理行动。为了实现所需的可用性,Pacemaker可以启动和停止资源和围栏节点。
-
Cluster tools: 这些工具为用户提供了一个与集群互动的界面。有各种命令行和图形(GUI)界面。然而,许多流行的开源集群文件系统使用了一个通用的分布式锁管理器(DLM),它直接使用了Corosync的消息传递和成员能力,以及Pacemaker的围栏节点能力。
大多数管理服务本身并不具有集群意识。然而,许多流行的开源集群文件系统使用了一个通用的分布式锁管理器(DLM),它直接使用了Corosync的消息传递和成员能力,以及Pacemaker的栅栏节点能力。
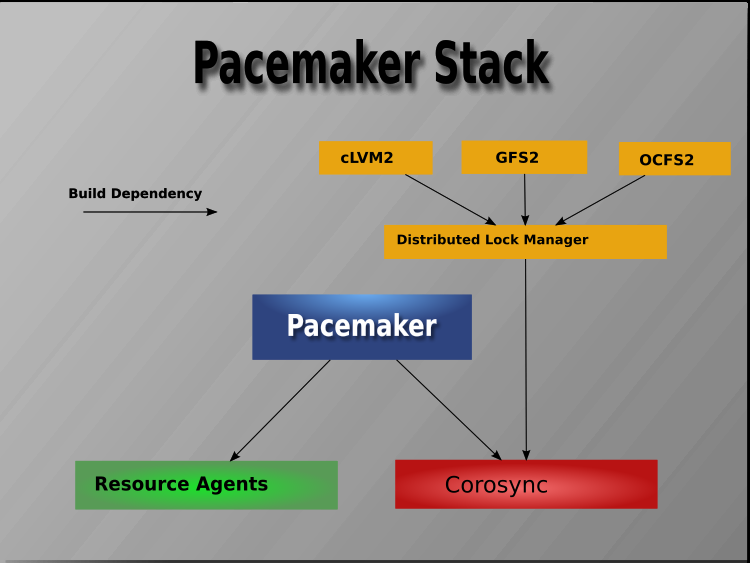
pacemaker架构
Pacemaker本身是由多个守护程序组成的,它们共同工作:
- pacemakerd
- pacemaker-attrd
- pacemaker-based
- pacemaker-controld
- pacemaker-execd
- pacemaker-fenced
- pacemaker-schedulerd
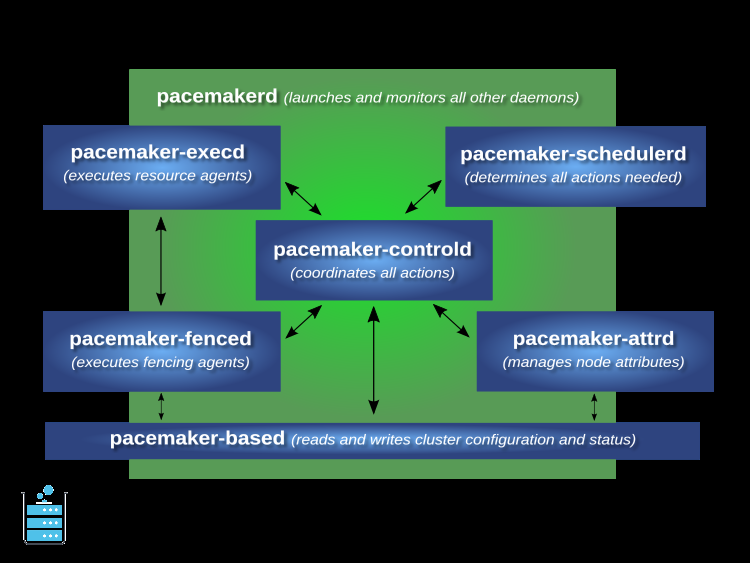
Pacemaker的主进程(peacemakerd)会生成所有其他守护进程,如果它们意外退出,则会重新生成它们。
集群信息库(CIB)是集群的配置以及所有节点和资源的状态的XML表示。CIB管理器(基于pacemaker)保持CIB在集群中的同步,并处理修改它的请求。
属性管理器(peacemaker-attrd)维护所有节点的属性数据库,使其在集群中保持同步,并处理修改它们的请求。这些属性通常被记录在CIB中。
给予CIB的快照作为输入,调度器( pacemaker-schedulerd)决定哪些行动是必要的,以实现集群的理想状态。
本地执行器(peacemaker-execd)处理在本地集群节点上执行资源代理的请求,并返回结果。
栅栏器(pacemaker-fenced)处理栅栏节点的请求。给定一个目标节点,击剑者决定哪个集群节点应该执行哪个击剑设备,并调用必要的击剑代理(直接,或通过请求其他节点上的击剑者同伴),并返回结果。
控制器(peacemaker-controld)是Pacemaker的协调者,维护集群成员的一致观点并协调所有其他组件。
Pacemaker通过选举其中一个控制器实例作为指定控制器(DC)来集中集群决策。如果选出的DC进程(或它所在的节点)失败,一个新的DC会很快建立。DC通过获取CIB的当前快照来响应集群事件,并将其反馈给调度器,然后要求执行者(直接在本地节点上,或通过请求其他节点上的控制器对等物)和Fencer来执行任何必要的行动。
Pacemaker守护程序在2.0版本中被重新命名。你可能仍然会发现对旧名称的引用,特别是在针对1.1版的文档中。
| Old name | New name |
|---|---|
| attrd | pacemaker-attrd |
| cib | pacemaker-based |
| crmd | pacemaker-controld |
| lrmd | pacemaker-execd |
| stonithd | pacemaker-fenced |
| pacemaker_remoted | pacemaker-remoted |
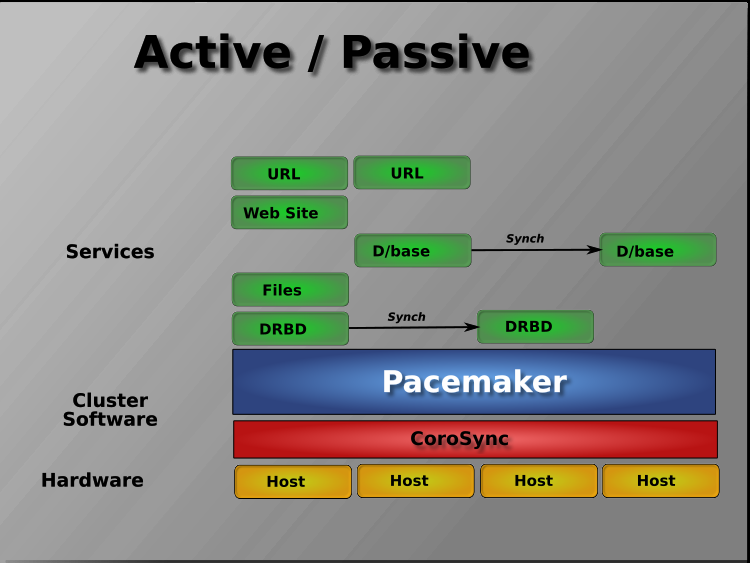
Pacemaker实际上支持任何节点冗余配置,包括Active/Active、Active/Passive、N+1、N+M、N-1和N-N。
主动/被动集群有两个(或更多)节点,使用Pacemaker和DRBD是一个具有成本效益的高可用性解决方案,适合许多情况。其中一个节点提供所需的服务,如果它发生故障,另一个节点将接管。
Pacemaker还支持共享故障转移设计中的多个节点,通过允许几个主动/被动集群合并,共享共同的备份节点来减少硬件成本。几个主动/被动集群结合起来,共享一个共同的备份节点。
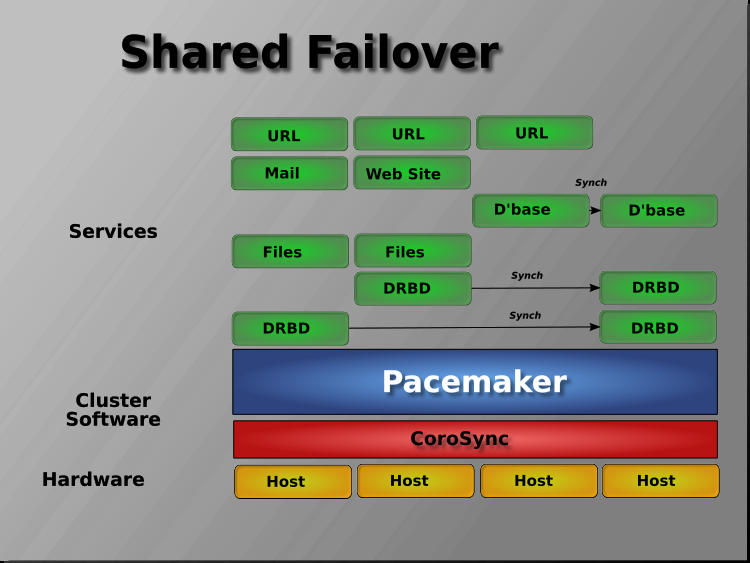
当共享存储可用时,每个节点都有可能被用于故障转移。Pacemaker甚至可以运行
服务的多个副本,以分散工作负荷。这有时被称为N对N冗余
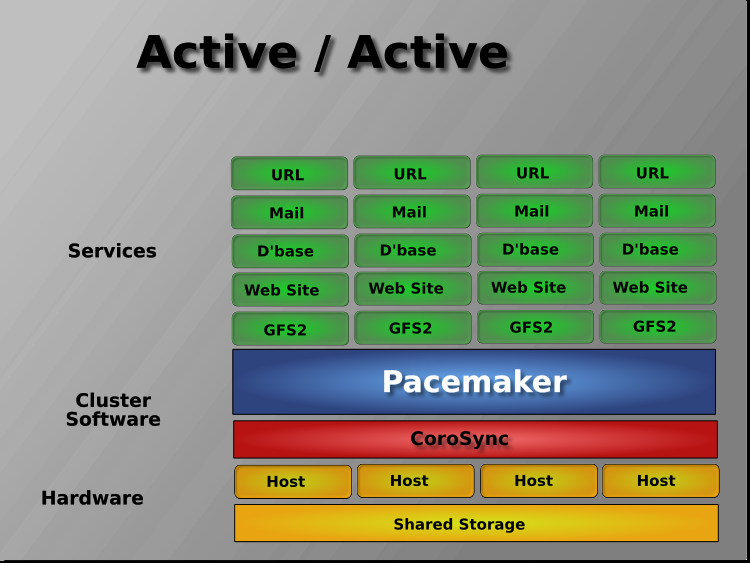
¶ 2.2 安装群集软件
大多数主要的 Linux 发行版在其标准软件包库中都有 pacemaker 包,或者该软件可以从源代码构建。详情请见安装wiki页面。
¶ 2.3 集群层
Pacemaker利用底层集群层有两个目的:
-
获得quorum
-
节点之间的信息传递
目前,该层只支持Corosync 2及以后的版本。
本文假设你已经在Corosync中配置了集群节点。高级别的集群管理工具可以为你配置Corosync。如果你想了解低级别的细节,请看Corosync文档。
¶ 2.4 配置pacemaker
Pacemaker的配置,即CIB,是以XML格式存储的。集群管理员有多种选择来修改配置,可以通过XML,也可以在更抽象(更容易被人理解)的层面上进行修改。
Pacemaker一旦保存了配置变化,就会对其作出反应。Pacemaker的命令行工具和大多数更高级别的工具提供了批量修改并一次性提交的能力,而不是进行一系列的小修改,这可能会导致避免不必要的行动,因为Pacemaker会对每个修改单独做出反应。
Pacemaker跟踪配置的修订,并将拒绝任何比当前修订更早的更新。因此,对配置的所有更改进行序列化是一个好主意。避免尝试同时更改,无论是在同一节点还是不同节点,无论是手动还是使用一些自动配置工具。
**注意:**没有必要在所有集群节点上更新配置。Pacemaker会立即将更改同步到集群的所有活动成员。为了减少带宽,集群只广播由你的改变而产生的增量更新,并使用校验和来确保每个副本是一致的。
¶ 2.4.1 使用高级工具配置
大多数用户将受益于使用由独立于 Pacemaker 的项目提供的高级工具。一些最常用的工具包括 crm shell、hawk 和 pcs。
关于如何使用这些项目配置 Pacemaker 的细节,请参见这些项目的文档。
¶ 2.4.2 使用 Pacemaker 的命令行工具进行配置
Pacemaker 提供了低级别的命令行工具来管理集群。大多数配置任务可以通过这些工具来完成,而不需要任何XML知识。
例如,要启用STONITH,可以运行:
# crm_attribute --name stonith-enabled --update 1
或者,要检查node1是否被允许运行资源,有:
# crm_standby --query --node node1
或者,要改变my-test-rsc的失败阈值,可以使用:
# crm_resource -r my-test-rsc --set-parameter migration-threshold --parameter-value 3 --meta
在本文件中,将酌情给出在特定情况下使用这些工具的例子。更多细节请参见手册页面。
参见用cibadmin编辑CIB的XML,了解如何用XML编辑CIB。
请参阅使用 crm_shadow 批量配置更改,了解如何进行一系列更改,然后一次性提交到实时集群。
使用CIB属性
虽然这些字段可以由用户写入,但在大多数情况下,集群会用 "正确 "的值覆盖用户指定的任何值。
要改变那些可以由用户指定的值,例如admin_epoch,应该使用:
# cibadmin --modify --xml-text '<cib admin_epoch="42"/>'
一套完整的CIB属性看起来会是这样的:
<cib crm_feature_set="3.0.7" validate-with="pacemaker-1.2"
admin_epoch="42" epoch="116" num_updates="1"
cib-last-written="Mon Jan 12 15:46:39 2015" update-origin="rhel7-1"
update-client="crm_attribute" have-quorum="1" dc-uuid="1">
查询和设置集群选项
集群选项可以使用crm_attribute工具进行查询和修改。要获得集群延迟的当前值,你可以运行:
# crm_attribute --query --name cluster-delay
更简单的写法是
# crm_attribute -G -n cluster-delay
如果找到一个值,你会看到这样的结果:
# crm_attribute -G -n cluster-delay
scope=crm_config name=cluster-delay value=60s
如果没有找到值,该工具将显示一个错误:
# crm_attribute -G -n clusta-deway
scope=crm_config name=clusta-deway value=(null)
Error performing operation: No such device or address
要使用一个不同的值(例如,30秒),只需运行:
# crm_attribute --name cluster-delay --update 30s
要回到集群的默认值,你可以删除该值,比如说:
# crm_attribute --name cluster-delay --delete
Deleted crm_config option: id=cib-bootstrap-options-cluster-delay name=cluster-delay
当选项被列出不止一次时
如果你看到类似以下的情况,这意味着你要修改的选项出现了不止一次
# crm_attribute --name batch-limit --delete
Please choose from one of the matches below and supply the 'id' with --id
Multiple attributes match name=batch-limit in crm_config:
Value: 50 (set=cib-bootstrap-options, id=cib-bootstrap-options-batch-limit)
Value: 100 (set=custom, id=custom-batch-limit)
在这种情况下,请按照屏幕上的指示来执行所要求的操作。要确定集群当前使用的是哪个值,请参考《pacemaker解释》中的 "规则 "一章。
¶ 2.4.3 从远程机器连接
只要Pacemaker安装在一台机器上,即使机器本身不在同一个集群中,也可以连接到集群。要做到这一点,只需设置一些环境变量并运行与在集群节点上工作时相同的命令。
| Environment Variable | Default | Description |
|---|---|---|
| CIB_user | $USER | The user to connect as. Needs to be part of the haclient group on the target host. |
| CIB_passwd | The user’s password. Read from the command line if unset. | |
| CIB_server | localhost | The host to contact |
| CIB_port | The port on which to contact the server; required. | |
| CIB_encrypted | TRUE | Whether to encrypt network traffic |
因此,如果c001n01是一个活动的集群节点,并且正在监听1234端口的连接,并且someuser是haclient组的成员,那么下面将提示someuser的密码并返回集群的当前配置:
# export CIB_port=1234; export CIB_server=c001n01; export CIB_user=someuser;
# cibadmin -Q
出于安全考虑,集群默认情况下不监听远程连接。如果你想允许远程访问,你需要设置remote-tls-port(加密的)或remote-clear-port(未加密的)CIB属性(即那些保存在cib标签中的属性,如num_updates和epoch)。
| CIB Property | Default | Description |
|---|---|---|
| remote-tls-port | Listen for encrypted remote connections on this port. | |
| remote-clear-port | Listen for plaintext remote connections on this port |
**重要提示:**管理主机上的Pacemaker版本必须与集群节点上的版本相同或更高。否则,它可能没有验证CIB所需的模式文件。
¶ 2.5 使用 Pacemaker 命令行工具
¶ 2.5.1 控制命令行输出
一些 pacemaker 的命令行工具已被转换为新的输出系统。这些工具包括 crm_mon 和 stonith_admin。这是一个正在进行的项目,随着时间的推移,更多的工具将被转换。这个系统让你用–output-as=来控制输出的格式,用–output-to=来控制输出的目的地。
可用的格式因工具而异,但至少所有使用新系统的工具都支持纯文本和XML。默认的格式是纯文本。默认目的地是stdout,但可以重定向到任何文件。有些格式支持命令行选项,用于改变输出的风格。比如说:
# crm_mon --help-output
Usage:
crm_mon [OPTION?]
Provides a summary of cluster's current state.
Outputs varying levels of detail in a number of different formats.
Output Options:
--output-as=FORMAT Specify output format as one of: console (default), html, text,
,
→ xml
--output-to=DEST Specify file name for output (or "-" for stdout)
--html-cgi Add text needed to use output in a CGI program
--html-stylesheet=URI Link to an external CSS stylesheet
--html-title=TITLE Page title
--text-fancy Use more highly formatted output
¶ 2.5.2 用crm_mon监控群集
crm_mon工具显示一个活动集群的当前状态。它可以按节点或资源来显示集群的状态,并且可以在单次或动态更新模式下使用。它还可以显示所执行的操作和有关失败的信息。
使用这个工具,你可以检查集群的状态是否不正常,并看看当你造成或模拟故障时它是如何反应的。
参见手册页或crm_mon --help的输出,以了解其许多选项的完整描述。
Cluster Summary:
* Stack: corosync
* Current DC: node2 (version 2.0.0-1) - partition with quorum
* Last updated: Mon Jan 29 12:18:42 2018
* Last change: Mon Jan 29 12:18:40 2018 by root via crm_attribute on node3
* 5 nodes configured
* 2 resources configured
Node List:
* Online: [ node1 node2 node3 node4 node5 ]
* Active resources:
* Fencing (stonith:fence_xvm): Started node1
* IP (ocf:heartbeat:IPaddr2): Started node2
Cluster Summary:
* Stack: corosync
* Current DC: node2 (version 2.0.0-1) - partition with quorum
* Last updated: Mon Jan 29 12:21:48 2018
* Last change: Mon Jan 29 12:18:40 2018 by root via crm_attribute on node3
* 5 nodes configured
* 2 resources configured
* Node List:
* Node node1: online
* Fencing (stonith:fence_xvm): Started
* Node node2: online
* IP (ocf:heartbeat:IPaddr2): Started
* Node node3: online
* Node node4: online
* Node node5: online
正如前面一章所提到的,DC是节点是做决定的地方。集群根据需要选出一个节点来做DC。对管理员来说,选择DC的唯一意义在于它的日志会有最多的关于为什么做出决定的信息。
设计crm_mon的HTML输出
crm_mon的HTML输出的各个部分都有一个与之相关的CSS类。不是所有的东西都有,但一些最有趣的部分有。在下面的例子中,每个节点的状态有一个在线类,每个资源的细节有一个rsc-ok类。
<h2>Node List</h2>
<ul>
<li>
<span>Node: cluster01</span><span class="online"> online</span>
</li>
<li><ul><li><span class="rsc-ok">ping (ocf::pacemaker:ping): Started</span></li></ul></li>
<li>
<span>Node: cluster02</span><span class="online"> online</span>
</li>
<li><ul><li><span class="rsc-ok">ping (ocf::pacemaker:ping): Started</span></li></ul></li>
</ul>
默认情况下,这些类的样式表被包含在HTML输出的头部。在上面的例子中,这个样式表的相关部分将被使用:
<style>
.online { color: green }
.rsc-ok { color: green }
</style>
如果你想覆盖部分或全部样式,只需创建你自己的样式表,将其放在网络服务器上,并将 --html-stylesheet=传递给crm_mon。这个链接会被添加到默认的样式表之后,所以你的改动会被优先考虑。你不需要复制整个默认的。只包括你想
变化。
¶ 2.5.3 用 cibadmin 编辑 CIB XML
修改配置的最灵活工具是 Pacemaker 的 cibadmin 命令。使用 cibadmin,您可以查询、添加、删除、更新或替换配置的任何部分。所有修改都会立即生效,所以不需要执行类似重载的操作。使用 cibadmin 最简单的方法是用它来保存当前配置到一个临时文件,用你喜欢的文本或 XML 编辑器编辑该文件,然后上传修改后的配置。
# cibadmin --query > tmp.xml
# vi tmp.xml
# cibadmin --replace --xml-file tmp.xml
一些较好的XML编辑器可以利用RELAX NG模式来帮助确保你所做的任何改变是有效的。描述配置的模式可以在 pacemaker.rng 中找到,它可能被部署在/usr/share/pacemaker 等位置,这取决于你的操作系统分布和你安装软件的方式。
如果你只想修改配置中的一个部分,你可以只查询和替换该部分,避免修改其他部分。
# cibadmin --query --scope resources > tmp.xml
# vi tmp.xml
# cibadmin --replace --scope resources --xml-file tmp.xml
要快速删除配置的一个部分,通过XML标签和id来确定你要删除的对象。例如,你可以在CIB中搜索所有与STONITH相关的配置
# cibadmin --query | grep stonith
<nvpair id="cib-bootstrap-options-stonith-action" name="stonith-action" value="reboot"/>
<nvpair id="cib-bootstrap-options-stonith-enabled" name="stonith-enabled" value="1"/>
<primitive id="child_DoFencing" class="stonith" type="external/vmware">
<lrm_resource id="child_DoFencing:0" type="external/vmware" class="stonith">
<lrm_resource id="child_DoFencing:0" type="external/vmware" class="stonith">
<lrm_resource id="child_DoFencing:1" type="external/vmware" class="stonith">
<lrm_resource id="child_DoFencing:0" type="external/vmware" class="stonith">
<lrm_resource id="child_DoFencing:2" type="external/vmware" class="stonith">
<lrm_resource id="child_DoFencing:0" type="external/vmware" class="stonith">
<lrm_resource id="child_DoFencing:3" type="external/vmware" class="stonith">
如果你想删除id为child_DoFencing的原始标签,你会运行:
# cibadmin --delete --xml-text '<primitive id="child_DoFencing"/>'
更多选项请参见 cibadmin man 页。
警告: 切勿直接编辑实时 cib.xml 文件。Pacemaker 会检测到这样的改变并拒绝使用该配置。
¶ 2.5.4 用crm_shadow批量修改配置
通常,在一次性更新实时配置之前,最好能预览一系列配置变化的效果。为此,crm_shadow创建了一个配置的 "影子 "副本,并安排所有的命令行工具来使用它。
要开始,只需调用crm_shadow --create,用你选择的名字,并按照屏幕上简单的
指示。影子副本是用一个名字来标识的,以便有可能拥有多个。
警告: 仔细阅读本节和屏幕上的说明;不这样做可能会导致破坏集群的活动配置!
# crm_shadow --create test
Setting up shadow instance
Type Ctrl-D to exit the crm_shadow shell
shadow[test]:
shadow[test] # crm_shadow --which
test
从这个时候开始,所有的集群命令将自动使用影子副本,而不是与集群的活动配置对话。一旦你完成了实验,你可以通过–commit选项使修改生效,或者使用–delete选项将其丢弃。再次强调,一定要仔细按照屏幕上的说明进行操作!
对于crm_shadow选项和命令的完整列表,可以用–help选项来调用它。
使用沙盒一次做出多个修改,丢弃这些修改,并验证真实的配置没有被触动。
shadow[test] # crm_failcount -r rsc_c001n01 -G
scope=status name=fail-count-rsc_c001n01 value=0
shadow[test] # crm_standby --node c001n02 -v on
shadow[test] # crm_standby --node c001n02 -G
scope=nodes name=standby value=on
shadow[test] # cibadmin --erase --force
shadow[test] # cibadmin --query
<cib crm_feature_set="3.0.14" validate-with="pacemaker-3.0" epoch="112" num_updates="2" admin_
,
→epoch="0" cib-last-written="Mon Jan 8 23:26:47 2018" update-origin="rhel7-1" update-client=
,
→"crm_node" update-user="root" have-quorum="1" dc-uuid="1">
<configuration>
<crm_config/>
<nodes/>
<resources/>
<constraints/>
</configuration>
<status/>
</cib>
shadow[test] # crm_shadow --delete test --force
Now type Ctrl-D to exit the crm_shadow shell
shadow[test] # exit
# crm_shadow --which
No active shadow configuration defined
# cibadmin -Q
<cib crm_feature_set="3.0.14" validate-with="pacemaker-3.0" epoch="110" num_updates="2" admin_
,
→epoch="0" cib-last-written="Mon Jan 8 23:26:47 2018" update-origin="rhel7-1" update-client=
,
→"crm_node" update-user="root" have-quorum="1">
<configuration>
<crm_config>
<cluster_property_set id="cib-bootstrap-options">
<nvpair id="cib-bootstrap-1" name="stonith-enabled" value="1"/>
<nvpair id="cib-bootstrap-2" name="pe-input-series-max" value="30000"/>
¶ 2.6 集群问题故障排除
¶ 2.6.1 日志记录
默认情况下,Pacemaker 将通知严重性和更高级别的消息记录到系统日志,并将信息严重性和更高级别的消息记录到详细日志,默认情况下是 /var/log/pacemaker/pacemaker.log。
可以在 Pacemaker 启动时通过环境变量控制日志记录选项。 这些设置的位置因操作系统而异(通常是 /etc/sysconfig/pacemaker 或 /etc/default/pacemaker)。
由于集群问题通常非常复杂,涉及多台机器、集群守护进程和托管服务,因此 Pacemaker 日志相当冗长以提供尽可能多的上下文。 使这些日志对用户更友好是一个持续的优先事项,但必然会有许多晦涩的低级信息,使它们难以理解。
Pacemaker 附带的默认日志轮换配置(通常安装在 /etc/logrotate.d/pacemaker 中)会在日志大小达到 100MB 时或每周轮换日志,以先到者为准。
如果您配置调试或(天堂禁止)跟踪级别的日志记录,日志会迅速增长。 由于轮换日志默认仅以年月日命名,因此如果您的日志在一天内超过 100MB,这可能会导致名称冲突。 您可以添加日期格式-%Y%m%d-%H 到旋转配置以避免这种情况。
¶ 2.6.2 过渡
理解 Pacemaker 集群如何运作的一个关键概念是转换。 转换是将集群从其当前状态带到所需状态(由配置表示)所需采取的一组操作。
每当发生相关事件(节点加入或离开集群、资源故障等)时,控制器将要求调度程序重新计算集群的状态,从而生成新的转换。 然后控制器以正确的顺序执行转换中的操作。
每个转换都可以在日志中通过一行来识别:
列为“输入”的文件是当时集群配置和状态 (CIB) 的快照。 该文件可以帮助确定为什么安排了特定的操作。 crm_simulate 命令(如使用 crm_simulate 模拟群集活动中所述)可用于重放该文件。
¶ 2.6.3 有关故障排除的更多信息
Andrew Beekhof 在他的博客 The Cluster Guy 中写了一系列关于故障排除的文章:
这些文章是为较早版本的 Pacemaker 编写的,因此许多要查找的特定名称和日志消息已更改,但这些概念仍然有效。
¶ 2.7 升级pacemaker集群(太长先不翻译)
¶ 2.7.1 pacemaker 版本管理
Pacemaker有一个整体的发布版本,加上某些内部组件的单独版本号。
-
pacemaker发布版本: 这个版本由三个数字组成(x.y.z)。
当至少有一些滚动升级不可能从上一个主要版本开始时,主要版本号(x.y.z中的x)会增加。例如,从1.0.8到1.1.15的滚动升级应该总是被支持的,但从1.0.8到2.0.0的滚动升级可能不可能。
当集群默认行为、工具行为和/或API接口(对于利用Pacemaker库的软件)发生重大变化时,次要版本(x.y.z中的y)会增加。
主要的好处是提醒你密切关注发布说明,看看你是否可能受到影响。版本计数器(x.y.z中的z)会随着Pacemaker的所有公开版本而增加,这通常包括错误修复和新功能
-
CRM功能集: 这个版本号适用于全集群节点之间的通信,用于避免混合版本集群的问题。
当不同版本的节点将无法工作时,主要版本号会增加(不允许滚动升级)。当混合版本的集群只允许在滚动升级时,小版本号会增加。小-小版本号被忽略,但允许资源代理检测集群对各种功能的支持。
Pacemaker确保运行时间最长的节点是集群的DC。这确保了在所有节点升级到支持新功能之前不会启用这些功能。
-
Pacemaker远程协议版本: 这个版本适用于Pacemaker Remote节点和集群之间的通信。当一个较老的集群节点在托管与较新的Pacemaker Remote节点的连接时,它就会出现问题。为了避免这些问题,Pacemaker Remote节点将只接受来自具有相同或较新Pacemaker Remote协议版本的集群节点的连接。
与全集群节点之间的CRM功能集差异不同,Pacemaker Remote节点和全集群节点之间的混合Pacemaker Remote协议版本是没有问题的,只要Pacemaker Remote节点有较早的版本。这可能是有用的,例如,在作为Pacemaker远程节点的旧操作系统版本中托管一个传统的应用程序。
-
XML模式版本: Pacemaker的配置语法–配置信息库(CIB)中允许的内容–有自己的版本。这允许配置语法随着时间的推移而发展,同时仍然允许具有较早配置的集群在不改变的情况下工作。
¶ 2.7.2 升级集群软件
有三种升级集群的方法,每种方法都有优点和缺点
| Method | Available between all versions | Can be used with Pacemaker Remote nodes | Service out age during upgrade | Service recovery during upgrade | Exercises failover logic | Allows change of messaging layer |
|---|---|---|---|---|---|---|
| Complete cluster shutdown | yes | yes | always | N/A | no | yes |
| Rolling (node by node) | no | yes | always | yes | yes | no |
| Detach and reattach | yes | no | only due to failure | no | no | yes |
彻底关闭群集
¶ 2.8 Resource Agents
¶ 2.8.1 行动完成
如果一个资源通过约束条件依赖于另一个资源,集群将把一个预期的结果解释为足以继续进行依赖行动。如果资源代理启动在服务不仅启动而且完全准备好执行其功能之前返回,或者如果资源代理停止在服务完全释放其对系统资源的所有要求之前返回,这可能导致时间问题。至少,在状态命令返回预期(启动或停止)结果之前,启动或停止不应返回。
¶ 2.8.2 OCF Resource Agents
自定义脚本的位置
OCF资源代理在/usr/lib/ocf/resource.d/$PROVIDER中找到。
在创建自己的代理时,我们鼓励你在/usr/lib/ocf/resource.d/下创建一个新的目录,这样它们就不会与现有供应商提供的代理混淆(或被覆盖)。
因此,举例来说,如果你选择了big-corp这个提供者的名字,并且想要一个名为big-app的新资源,你将创建一个名为/usr/lib/ocf/resource.d/big-corp/big-app的资源代理并定义一个资源:
行动
所有OCF资源代理都需要实现以下动作
| Action | Description | Instructions |
|---|---|---|
| start | Start the resource | Return 0 on success and an appropriate error code otherwise. Must not report success until the resource is fully active. |
| stop | Stop the resource | Return 0 on success and an appropriate error code otherwise. Must not report success until the resource is fully stopped |
| monitor | Check the resource’s state | Exit 0 if the resource is running, 7 if it is stopped, and any other OCF exit code if it is failed. NOTE: The monitor script should test the state of the resource on the |
| metadata | Describe the resource | Provide information about this resource in the XML format defined by the OCF |
OCF资源代理可以选择性地实现额外的动作。有些只用于高级资源类型,如克隆。
| Action | Description | Instructions |
|---|---|---|
| validate all | This should validate the instance parameters provided. | Return 0 if parameters are valid, 2 if not valid,and 6 if resource is not configured. |
| promote | Bring the local instance of a promotable clone resource to the promoted role. | Return 0 on success |
| demote | Bring the local instance of a promotable clone resource to the unpromoted role | Return 0 on success |
| notify | Used by the cluster to send the agent pre- and post- notification events telling the resource what has happened and will happen. | Must not fail. Must exit with 0 |
| reload | Reload the service’s own config. | Not used by Pacemaker |
| reload-agent | Make effective any changes in instance parameters marked as reloadable in the agent’s metadata. | This is used when the agent can handle a change in some of its parameters more efficiently than stopping and starting the resource. |
| recover | Restart the service | Not used by Pacemaker |
**重要提示:**如果你创建了一个新的OCF资源代理,请使用ocf-tester来验证该代理是否正确符合OCF标准。
OCF的返回代码是如何解释的?
集群做的第一件事是将返回代码与预期结果进行核对。如果结果与预期值不一致,那么操作就被认为是失败的,并启动恢复行动。
有三种类型的故障恢复:
| Type | Description | Action Taken by the Cluster |
|---|---|---|
| soft | A transient error occurred | Restart the resource or move it to a new location |
| hard | A non-transient error that may be specific to the current node | Move the resource elsewhere and prevent it from being retried on the current node |
| fatal | A non-transient error that will be common to all cluster nodes (e.g. a bad configuration was specified) | Stop the resource and prevent it from being started on any cluster node |
OCF返回代码
下表列出了不同的OCF返回代码以及集群在收到失败代码时将启动的恢复类型。虽然有悖常理,但即使是返回0(又称OCF_SUCCESS)的操作也可以被认为是失败的,如果0不是预期的返回值。
| Exit Code | OCF Alias | Description | Recovery |
|---|---|---|---|
| 0 | |||
| 1 | |||
| 2 | |||
| 3 | |||
| 4 | |||
| 5 | |||
| 6 | |||
| 7 | |||
| 8 | |||
| 9 | |||
| 190 | |||
| 191 | |||
| other | none |
上述恢复处理的例外情况:
-
发现资源处于活动状态(或处于晋升角色)的探针(非经常性的监控行动)将不会导致恢复行动,除非在其他地方也发现它处于活动状态。
-
当发现一个资源不止一次处于活动状态时,采取的恢复行动由该资源的多重活动属性决定。
-
返回OCF_ERR_UNIMPLEMENTED的重复动作不会导致任何类型的恢复。
-
返回 "降级 "代码之一的操作将被视为与返回成功相同,但状态输出将表明资源已降级。
¶ 2.8.3 LSB资源代理(启动脚本)
LSB规范
LSB规范的相关部分包括对这里列出的所有返回代码的描述。
假设some_service配置正确且当前不活动,下面的顺序将帮助你确定它是否与LSB兼容:
-
Start (stopped):
# /etc/init.d/some_service start ; echo "result: $?"- 服务启动了吗?
- echo命令是否打印了结果:0(除了init脚本的常规输出外)?
-
Status (running):
# /etc/init.d/some_service status ; echo "result: $?"-
脚本是否接受该命令?
-
脚本是否显示该服务正在运行?
-
echo命令是否打印了结果:0(除了init脚本的常规输出外)?
-
-
Start (running):
# /etc/init.d/some_service start ; echo "result: $?"- 该服务还在运行吗?
- echo命令是否打印了结果:0(除了init脚本的常规输出外)?
-
Stop (running):
# /etc/init.d/some_service stop ; echo "result: $?"- 该服务还在运行吗?
- echo命令是否打印了结果:0(除了init脚本的常规输出外)?
-
Status (stopped):
# /etc/init.d/some_service status ; echo "result: $?"- 该脚本是否接受了该命令?
- 该脚本是否表明该服务没有在运行?
- echo命令的打印结果是否为:3(除了init脚本的常规输出)?
-
Stop (stopped):
# /etc/init.d/some_service stop ; echo "result: $?"- 该服务是否仍然已停止?
- echo命令打印的结果是否为:0(除了init脚本的常规输出)?
-
Status (failed):
此步骤不容易进行测试,并依赖于对脚本的手动检查。
该脚本可以使用LSB规范中列出的错误代码(除3除外)来表明它是活动的,但失败了。这告诉集群,在将资源移动到另一个节点之前,它需要先在现有节点上停止资源。
如果上述任何一个问题的答案都是否定的,那么该脚本就不兼容LSB。然后,您可以选择修复该脚本或基于现有的脚本编写一个OCF代理。
¶ 2.9 pcs和crm shell的快速对比
pcs和crm shell是pacemaker中流行的两个高级命令行接口。每个都有自己的语法;本章给出了如何使用任何一个任务完成相同任务的快速比较。一些例子还显示了使用低级Pacmaker命令行工具的等效命令。
这些示例显示了最简单的语法;有关所有可能的选项,请参见各自的手册页。
¶ 2.9.1显示集群配置和状态
查看配置(原始XML)
crmsh # crm configure show xml
pcs # pcs cluster cib
pacemaker # cibadmin -Q
查看配置(友好显示)
crmsh # crm configure show
pcs # pcs config
查看集群状态
crmsh # crm status
pcs # pcs status
pacemaker # crm_mon -1
¶ 2.9.2 管理节点
使节点“pcmk-1”处于待机状态
crmsh # crm node standby pcmk-1
pcs-0.9 # pcs cluster standby pcmk-1
pcs-0.10 # pcs node standby pcmk-1
pacemaker # crm_standby -N pcmk-1 -v on
从待机模式中删除节点“pcmk-1”
crmsh # crm node online pcmk-1
pcs-0.9 # pcs cluster unstandby pcmk-1
pcs-0.10 # pcs node unstandby pcmk-1
pacemaker # crm_standby -N pcmk-1 -v off
¶ 2.9.3 管理集群优先级
将"stonith-enabled"的集群属性设置为"false"
crmsh # crm configure property stonith-enabled=false
pcs # pcs property set stonith-enabled=false
pacemaker # crm_attribute -n stonith-enabled -v false
¶ 2.9.4 查看resource agent信息
列出resource agent(RA)类
crmsh # crm ra classes
pcs # pcs resource standards
pacmaker # crm_resource --list-standards
按标准列出可用resource agent (RA)
crmsh # crm ra list ocf
pcs # pcs resource agents ocf
pacemaker # crm_resource --list-agents ocf
按 OCF 提供商列出可用resource agents (RAs)
crmsh # crm ra list ocf pacemaker
pcs # pcs resource agents ocf:pacemaker
pacemaker # crm_resource --list-agents ocf:pacemaker
列出可用的resource agents参数
crmsh # crm ra info IPaddr2
pcs # pcs resource describe IPaddr2
pacemaker # crm_resource --show-metadata ocf:heartbeat:IPaddr2
如果有多个具有相同名称的 RA 可用,您还可以将完整的 class:provider:type 格式与 crmsh 和 pcs 一起使用
显示可用的Fence Agent参数
crmsh # crm ra info stonith:fence_ipmilan
pcs # pcs stonith describe fence_ipmilan
¶ 2.9.5 管理resource
创建resource
crmsh # crm configure primitive ClusterIP ocf:heartbeat:IPaddr2 \
params ip=192.168.122.120 cidr_netmask=24 \
op monitor interval=30s
pcs # pcs resource create ClusterIP IPaddr2 ip=192.168.122.120 cidr_netmask=24
pcs 自动确定标准和提供者 (ocf:heartbeat),因为 IPaddr2 是唯一的,并根据代理的元数据自动创建操作(包括监控)。
显示所有resources的配置
crmsh # crm configure show
pcs-0.9 # pcs resource show --full
pcs-0.10 # pcs resource config
显示一个resource的配置
crmsh # crm configure show ClusterIP
pcs-0.9 # pcs resource show ClusterIP
pcs-0.10 # pcs resource config ClusterIP
显示Fencing Resources的配置
crmsh # crm resource status
pcs-0.9 # pcs stonith show --full
pcs-0.10 # pcs stonith config
启用resource
crmsh # crm resource start ClusterIP
pcs # pcs resource enable ClusterIP
pacemaker # crm_resource -r ClusterIP --set-parameter target-role --meta -v Started
停用resource
crmsh # crm resource stop ClusterIP
pcs # pcs resource disable ClusterIP
pacemaker # crm_resource -r ClusterIP --set-parameter target-role --meta -v Stopped
移除resource
crmsh # crm configure delete ClusterIP
pcs # pcs resource delete ClusterIP
修改resource的实例参数
crmsh # crm resource param ClusterIP set clusterip_hash=sourceip
pcs # pcs resource update ClusterIP clusterip_hash=sourceip
pacemaker # crm_resource -r ClusterIP --set-parameter clusterip_hash -v sourceip
crmsh 还有一个编辑命令,它通过可配置的文本编辑器编辑简化的 CIB 语法(与命令行相同的命令)。
以交互式的方式修改resource的实例参数
crmsh # crm configure edit ClusterIP
使用 crmsh 的交互式 shell 模式,可以在提交到实时配置之前编辑和验证多个更改:
以交互式的方式进行多个配置更改
crmsh # crm configure
crmsh # edit
crmsh # verify
crmsh # commit
删除resource的实例参数
crmsh # crm resource param ClusterIP delete nic
pcs # pcs resource update ClusterIP nic=
pacemaker # crm_resource -r ClusterIP --delete-parameter nic
列出当前resource默认值
crmsh # crm configure show type:rsc_defaults
pcs # pcs resource defaults
pacemaker # cibadmin -Q --scope rsc_defaults
设置resource默认值
crmsh # crm configure rsc_defaults resource-stickiness=100
pcs # pcs resource defaults resource-stickiness=100
列出当前操作默认值
crmsh # crm configure show type:op_defaults
pcs # pcs resource op defaults
pacemaker # cibadmin -Q --scope op_defaults
设置操作默认值
crmsh # crm configure op_defaults timeout=240s
pcs # pcs resource op defaults timeout=240s
为resource启用resource agent跟踪
crmsh # crm resource trace Website
清除resource的失败计数
crmsh # crm resource cleanup Website
pcs # pcs resource cleanup Website
pacemaker # crm_resource --cleanup -r Website
创建克隆resource
crmsh # crm configure clone WebIP ClusterIP meta globally-unique=true clone-max=2 clone-node-max=2
pcs # pcs resource clone ClusterIP globally-unique=true clone-max=2 clone-node-max=2
创建一个可推广的克隆resource
crmsh # crm configure ms WebDataClone WebData \
meta master-max=1 master-node-max=1 \
clone-max=2 clone-node-max=1 notify=true
pcs-0.9 # pcs resource master WebDataClone WebData \
master-max=1 master-node-max=1 \
clone-max=2 clone-node-max=1 notify=true
pcs-0.10 # pcs resource promotable WebData WebDataClone \
promoted-max=1 promoted-node-max=1 \
clone-max=2 clone-node-max=1 notify=true
如果在命令行中省略,pcs 将自动生成克隆名称。
¶ 2.9.6 管理约束
创建主机托管约束
crmsh # crm configure colocation website-with-ip INFINITY: WebSite ClusterIP
pcs # pcs constraint colocation add ClusterIP with WebSite INFINITY
创建一个基于角色的托管约束
crmsh # crm configure colocation another-ip-with-website inf: AnotherIP WebSite:Master
pcs # pcs constraint colocation add Started AnotherIP with Promoted WebSite INFINITY
创建排序约束
crmsh # crm configure order apache-after-ip mandatory: ClusterIP WebSite
pcs # pcs constraint order ClusterIP then WebSite
基于角色创建排序约束
crmsh # crm configure order ip-after-website Mandatory: WebSite:Master AnotherIP
pcs # pcs constraint order promote WebSite then start AnotherIP
创建位置约束
crmsh # crm configure location prefer-pcmk-1 WebSite 50: pcmk-1
pcs # pcs constraint location WebSite prefers pcmk-1=50
基于角色创建位置约束
crmsh # crm configure location prefer-pcmk-1 WebSite rule role=Master 50: \#uname eq pcmk-1
pcs # pcs constraint location WebSite rule role=Promoted 50 \#uname eq pcmk-1
将资源移动到特定节点(通过创建位置约束)
crmsh # crm resource move WebSite pcmk-1
pcs # pcs resource move WebSite pcmk-1
pacemaker # crm_resource -r WebSite --move -N pcmk-1
将资源从其当前节点中移动出去(通过创建位置约束)
crmsh # crm resource ban Website pcmk-2
pcs # pcs resource ban Website pcmk-2
pacemaker # crm_resource -r WebSite --move
删除通过移动资源而创建的任何约束条件
crmsh # crm resource unmove WebSite
pcs # pcs resource clear WebSite
pacemaker # crm_resource -r WebSite --clear
¶ 2.9.7 高级配置
按类型操作配置元素
列出包含ID的约束
pcs # pcs constraint list --full
通过ID删除约束
pcs # pcs constraint remove cli-ban-Website-on-pcmk-1
crmsh # crm configure remove cli-ban-Website-on-pcmk-1
crmsh的显示和编辑命令可以用于按类型管理资源和约束:
显示配置元素
crmsh # crm configure show type:primitive
crmsh # crm configure edit type:colocation
批处理更改
进行多次更改并一起应用
crmsh # crm
crmsh # cib new drbd_cfg
crmsh # configure primitive WebData ocf:linbit:drbd params drbd_resource=wwwdata \
op monitor interval=60s
crmsh # configure ms WebDataClone WebData meta master-max=1 master-node-max=1 \
clone-max=2 clone-node-max=1 notify=true
crmsh # cib commit drbd_cfg
crmsh # quit
pcs # pcs cluster cib drbd_cfg
pcs # pcs -f drbd_cfg resource create WebData ocf:linbit:drbd drbd_resource=wwwdata \
op monitor interval=60s
pcs-0.9 # pcs -f drbd_cfg resource master WebDataClone WebData \
master-max=1 master-node-max=1 clone-max=2 clone-node-max=1 notify=true
pcs-0.10 # pcs -f drbd_cfg resource promotable WebData WebDataClone \
promoted-max=1 promoted-node-max=1 clone-max=2 clone-node-max=1 notify=true
pcs # pcs cluster cib-push drbd_cfg
模板创建
基于相同类型的现有基元创建资源模板
crmsh # crm configure assist template ClusterIP AdminIP
日志分析
显示有关最近集群事件的信息
crmsh # crm history
crmsh # peinputs
crmsh # transition pe-input-10
crmsh # transition log pe-input-10
配置脚本
编写多步骤集群配置脚本
crmsh # crm script show apache
crmsh # crm script run apache \
id=WebSite \
install=true \
virtual-ip:ip=192.168.0.15 \
database:id=WebData \
database:install=true