¶ slurm–云端调度指南
¶ 概述
Slurm有能力支持一个按需增长和收缩的集群,通常依靠亚马逊弹性计算云(Amazon EC2)、谷歌云平台或微软Azure等服务获取资源。这些资源可以与现有的集群结合起来,以处理多余的工作负荷(cloud bursting),或者它可以作为一个独立的自足集群运行。可以实现良好的响应性和吞吐量,而你只需为所需的资源付费。
本文件的其余部分描述了关于Slurm的基础设施的细节,这些基础设施可用于支持云调度。
Slurm的云调度逻辑在很大程度上依赖于现有的节电逻辑。强烈建议查看Slurm的节电指南。这个逻辑在需要使用节点时启动程序,在不再需要这些节点时启动另一个程序。对于云端调度,这些程序需要从云端配置资源,并通知Slurm节点的名称和网络地址,随后将节点放回云端。大多数支持云调度的Slurm变化是支持节点寻址的变化,这些变化可以改变。
¶ Slurm配置
有很多方法可以配置Slurm对资源的使用。关于这些选项的更多细节,请参见slurm.conf man页。一些一般的Slurm配置参数是有意义的,包括
CommunicationParameters=NoAddrCache
- 默认情况下,Slurm在成功建立一个节点的网络地址后会对该节点的网络地址进行缓存。这个选项禁用了缓存,Slurm将在每次连接时查找节点的网络地址。这是很有用的,例如在云环境中,节点地址会从DNS中出现和消失。
ReconfigFlags=KeepPowerSaveSettings
- 如果设置,"scontrol reconfig"命令将保留SuspendExcNodes、SuspendExcParts和SuspendExcStates的当前状态。
ResumeFailProgram
- 当节点在
ResumeTimeout前恢复失败时将被执行的程序。该程序的参数将是失败节点的名称(使用Slurm的hostlist表达式格式)。
ResumeFailProgram
-
当一个节点已经被分配并且应该可以被使用时执行的程序。如果slurmd守护进程未能在配置的
SlurmdTimeout值内响应更新的BootTime,该节点将被置于下降状态,请求该节点的作业将被重新排队。如果节点没有实际重启(即配置了多个slurmd时),用"-b "选项启动slurmd可能是有用的。程序的参数是要开机的节点名称(使用Slurm的hostlist表达式格式)。通过读取SLURM_RESUME_FILE环境变量指定的临时文件,可以得到JSON格式的作业到节点的映射。
例如,请看squeue man页中关于Oversubscribe的可能值。SLURM_RESUME_FILE=/proc/1647372/fd/7: { "all_nodes_resume" : "cloud[1-3,7-8]", "jobs" : [ { "extra" : "An arbitrary string from --extra", "features" : "c1,c2", "job_id" : 140814, "nodes_alloc" : "cloud[1-4]", "nodes_resume" : "cloud[1-3]", "oversubscribe" : "OK", "partition" : "cloud", "reservation" : "resv_1234" }, { "extra" : null, "features" : "c1,c2", "job_id" : 140815, "nodes_alloc" : "cloud[1-2]", "nodes_resume" : "cloud[1-2]", "oversubscribe" : "OK", "partition" : "cloud", "reservation" : null } { "extra" : null, "features" : null "job_id" : 140816, "nodes_alloc" : "cloud[7-8]", "nodes_resume" : "cloud[7-8]", "oversubscribe" : "NO", "partition" : "cloud_exclusive", "reservation" : null } ] }
ResumeTimeout
- 从发出节点恢复请求到节点实际可以使用之间允许的最大时间(秒)。在这个时间范围内没有回应的节点将被标记为停机,并重新安排该节点上的工作。在这个时间段后重新启动的节点将被标记为
DOWN,理由是 “节点意外地重新启动”。默认值是60秒。
SlurmctldParameters=cloud_dns
- 默认情况下,Slurm期望云节点的网络地址在创建节点之前不会被知道,Slurm将被通知节点的地址(例如,
scontrol update nodename=<name> nodeaddr=<addr>)。由于Slurm通信依赖于在slurm.conf中找到的节点配置,Slurm将在等待所有节点启动后,告诉客户端命令,每个节点的IP地址。然而,在节点在DNS中的环境中,通过配置这个选项可以避免这个步骤。
SlurmctldParameters=idle_on_node_suspend
- 在用
SuspendProgram暂停节点时,将节点标记为空闲,无论当前状态如何,这样节点就有资格在以后的时间里被恢复。
SuspendExcNodes
- 不受暂停/恢复逻辑约束的节点。这可以用来避免暂停和恢复不在云中的节点。另外,暂停/恢复程序可以区别对待本地节点和从云中配置的节点。使用Slurm的hostlist表达式来识别节点,可选择
": "分隔符和要从前面的范围中排除的节点数。例如,"nid[10\-20]:4 "将阻止"nid[10\-20]"中的4个可用的节点(即IDLE而不是DOWN、DRAINING或已经断电)被断电。可以在逗号分隔的列表中指定多个节点集,包括或不包括计数(例如"nid[10\-20]:4,nid[80\-90]:2")。默认情况下,没有节点被排除。这个值可以用scontrol更新。参见ReconfigFlags=KeepPowerSaveSettings来设置持久性。
SuspendExcParts
- 带有节点的分区列表,永远不会放在省电模式下。可以使用逗号分隔符来指定多个分区。默认情况下,没有节点被排除在外。这个值可以用
scontrol来更新。参见ReconfigFlags=KeepPowerSaveSettings以设置持久性。
SuspendExcStates
- 指定不自动断电的节点状态。有效的状态包括
CLOUD、DOWN、DRAIN、DYNAMIC_FUTURE、DYNAMIC_NORM、FAIL、INVALID_REG、MAINTENANCE、NOT_RESPONDING、PERFCTRS、PLANNED和RESPED。默认情况下,这些状态中的任何一个,如果在SuspendTime内闲置,都会被关闭电源。这个值可以用scontrol更新。参见ReconfigFlags=KeepPowerSaveSettings来设置持久性。
SuspendProgram
- 当一个节点不再需要并且可以放弃给云的时候所执行的程序。
SuspendTime
- 在请求放弃一个节点之前,该节点将被闲置或关闭的时间间隔。单位是秒。
SuspendTimeout
- 从发出节点暂停请求到关闭节点之间允许的最大时间(以秒为单位)。这时节点必须准备好,以便根据新工作的需要发出恢复请求。默认值是30秒。
TCPTimeout
- 允许建立TCP连接的时间。这个值可能需要从默认值(2秒)增加,以考虑本地站点和云中机器之间的延迟。
TreeWidth
- 由于slurmd守护进程不知道云中其他节点的网络地址,每个节点上的slurmd守护进程应该直接发送消息,而不是在彼此之间转发这些消息。要做到这一点,将TreeWidth配置为一个至少与最大节点数一样大的数字。该值不得超过65533。
一些值得关注的节点参数包括:
Feature
节点特征可以与从云中获取的资源相关联,用户工作可以通过"–约束 "选项指定他们对资源使用的偏好。
NodeName
这是Slurm用来指代节点的名称。为了方便起见,建议使用包含数字后缀的名称。NodeAddr和NodeHostname不应该被设置,但将在以后使用脚本进行配置。
State
要按需添加的节点应该有一个 "CLOUD "的状态。这些节点实际上不会出现在Slurm命令中,直到它们被配置为使用之后。
Weight
每个节点都可以配置一个权重,表示使用该资源的可取性。权重较低的节点会在权重较高的节点之前使用。
一些感兴趣的分区参数包括:
PowerDownOnIdle
如果设置为YES,那么从这个分区分配的节点将在成为IDLE时立即被请求关闭电源。掉电请求会阻止对节点的进一步调度,直到它被SuspendProgram放入省电模式。
ResumeTimeout, SuspendTimeout 和 SuspendTime
这些可以在分区级别上应用。如果一个节点在多个分区中,并且这些选项被配置在分区上,那么较高的值将被用于该节点。如果该选项没有设置,它将使用全局设置。如果没有设置全局的SuspendTime,在一个分区上配置SuspendTime将启用省电模式。
要按需获取的节点可以放在它们自己的Slurm分区中。这种操作模式只有在用户要求的情况下才能使用这些节点。请注意,作业可以提交给多个分区,并将使用哪个分区的资源,就允许更快地启动。一个样本配置,当工作负载超过可用资源时,从云中添加节点。用户可以通过使用"--constraint "选项明确请求本地资源或来自云的资源。
# Excerpt of slurm.conf
SelectType=select/cons_res
SelectTypeParameters=CR_CORE_Memory
SuspendProgram=/usr/sbin/slurm_suspend
ResumeProgram=/usr/sbin/slurm_suspend
SuspendTime=600
SuspendExcNodes=tux[0-127]
TreeWidth=128
NodeName=DEFAULT Sockets=1 CoresPerSocket=4 ThreadsPerCore=2
NodeName=tux[0-127] Weight=1 Feature=local State=UNKNOWN
NodeName=ec[0-127] Weight=8 Feature=cloud State=CLOUD
PartitionName=debug MaxTime=1:00:00 Nodes=tux[0-32] Default=yes
PartitionName=batch MaxTime=8:00:00 Nodes=tux[0-127],ec[0-127] Default=no
默认情况下,当启用省电模式时,Slurm会尝试 "暂停 "所有节点,除非被SuspendExcNodes或SuspendExcParts排除。对于来自内部的突发情况,这可能很棘手,必须记住将内部的节点添加到排除选项中。通过将全局SuspendTime设置为INFINITE,并在云端特定分区上配置SuspendTime,你可以避免排除节点。
如果全局启用了省电模式,通过将SuspendTime设置为INFINITE,就可以禁用特定分区的省电模式。
¶ 操作细节
当slurmctld守护进程启动时,所有状态为CLOUD的节点将被包含在其内部表格中,但这些节点记录在分配给某些工作之前,不会被用户命令看到或被应用程序使用。分配后,ResumeProgram被执行,应该做以下工作:
-
启动节点
-
配置并启动Munge(取决于配置)。
-
在节点上安装Slurm配置文件,slurm.conf。注意,配置文件在所有节点上通常是相同的,不包括云中任何节点的NodeAddr或NodeHostname配置参数。在这个节点上执行的Slurm命令只需要与SlurmctldHost上的slurmctld守护程序通信。
-
通知slurmctld守护进程该节点的主机名和网络地址:
scontrol update nodename=ec0 nodeaddr=123.45.67.89 nodehostname=whatever注意,除非使用
"-c"(冷启动)选项,否则在重新启动slurmctld守护进程时,由scontrol命令设置的节点地址和主机名信息会被保留。 -
在节点上启动slurmd守护进程
SuspendProgram只需要将节点重新交还给云端。
一个环境变量SLURM_NODE_ALIASES包含节点名称、通信地址和主机名的集合。该变量由salloc、sbatch和srun设置。然后它被srun用来确定作业启动通信信息的目的地。这个环境变量只为从云中分配的节点设置。如果一个作业被分配了一些来自本地集群的资源和其他来自云的资源,只有那些来自云的节点会出现在SLURM_NODE_ALIASES中。每一组名称和地址用逗号隔开,组内的元素用冒号隔开。比如说:
SLURM_NODE_ALIASES=ec0:123.45.67.8:foo,ec2:123.45.67.9:bar
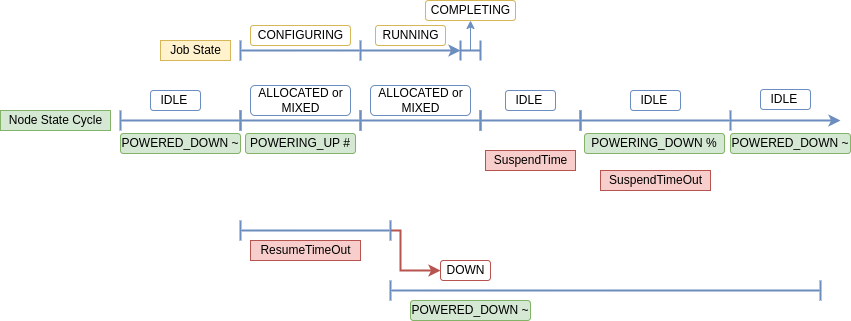
¶ 云节点的生命周期
当启用省电模式时,一个云节点会在不同的状态下移动。一个节点可以在同一时间有多个状态与之相关。在 "sinfo"中查看节点详情时,与节电相关的状态会用符号标示出来。
云节点在自动缩放操作期间可能具有的节点状态列表:
| STATE | Power Saving Symbol | Description |
|---|---|---|
| IDLE | The node is not allocated to any jobs and is available for use. | |
| POWERED_DOWN | ~ | The node is powered off (node has been relinquished to the cloud). |
| ALLOCATED | All CPUS on the node have been allocated to one or more jobs. | |
| MIXED | The node has some of its CPUs allocated while others are idle. | |
| POWERING_UP | # | The node is in the process of being powered up. |
| COMPLETING | All jobs associated with this node are in the process of COMPLETING. This node state will be removed when all of the job’s processes have terminated and the Slurm epilog program (if any) has terminated. | |
| POWERING_DOWN | % | The node is in the process of powering down and not capable of running any jobs. |
| DOWN | The node is unavailable for use. Slurm can automatically place nodes in this state if some failure occurs. System administrators may also explicitly place nodes in this state. If a node resumes normal operation, Slurm can automatically return it to service (See ReturnToService). A DOWN Cloud node can be changed to IDLE using the scontrol command: scontrol update node=[nodename] state=idle |
在手动省电操作期间,节点可能具有的其他状态:
| STATE | Power Saving Symbol | Description |
|---|---|---|
| DRAINING | The node is currently executing a job, but will not be allocated additional jobs. The node state will be changed to state DRAINED when the last job on it completes. Nodes enter this state per system administrator request. | |
| POWER_DOWN | ! | When the node is no longer running jobs, run the SuspendProgram. |
| DRAINED | The node is unavailable for use per system administrator request. |
一个云节点开始时处于IDLE和POWERED_DOWN(~)状态。在这种状态下,没有实际的节点存在,因为节点在云中等待着被供应。然而,IDLE状态表明它有资格进行工作。
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
debug* up infinite 100 idle~ c1-compute-0-[0-99]
当Slurm将一个作业安排到这个状态的节点上时,该节点将移动到ALLOCATED或MIXED(基于所有的CPU是否被分配)和POWERING_UP(#)。
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
debug* up infinite 1 alloc# c1-compute-0-0>
debug* up infinite 99 idle~ c1-compute-0-[1-99]
计划中的工作在等待节点上电时处于CONFIGURING状态。
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
182 debug wrap nick_sch CF 0:01 2 c1-compute-0-0
上电后,节点向Slurm控制器注册,POWERING_UP(#)被移除。工作将在节点注册后开始运行+30秒的最大值,基于节点注册和工作开始的时间。
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
debug* up infinite 1 alloc c1-compute-0-0
debug* up infinite 99 idle~ c1-compute-0-[1-99]
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
182 debug wrap nick_sch R 0:04 2 c1-compute-0-0
一旦作业完成,如果没有其他作业被安排到该节点,该节点就会移动到IDLE状态,SuspendTime的定时器就会开始。"scontrol show node "输出显示LastBusyTime,即节点停止运行作业并成为空闲状态的时间戳。
当达到SuspendTime时,节点将移动到IDLE+POWERING_DOWN(%)。在这个时候,SuspendProgram将执行。在POWERING_DOWN状态被移除之前,该节点没有资格被分配。
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
debug* up infinite 1 idle% c1-compute-0-0
debug* up infinite 99 idle~ c1-compute-0-[1-99]
¶ 上电和下电故障
如果在POWERING_UP或POWERING_DOWN阶段出现故障,节点可能进入DOWN状态。ResumeTimeout控制Slurm等待多久,直到节点被期望注册。如果节点未能在该时间内注册,就会被标记为DOWN,并且在该节点上安排的作业会被重新排队。要将节点移回IDLE状态,请运行:
scontrol update node=[nodename] state=resume
SuspendTimeout控制Slurm何时会认为节点已被放弃给云。在这一点上,该节点被标记为IDLE和POWERED_DOWN。这个步骤可以通过手动运行 "scontrol update node=[nodename] state=resume "来加速,或者在SuspendProgram脚本中。
¶ 手动节电
通过使用 "scontrol update"将节点的状态设置为以下状态,可以手动开启和关闭节点的电源:
POWER_DOWN、POWER_UP、POWER_DOWN_ASAP、或POWER_DOWN_FORCE
POWER_DOWN或POWER_UP使用配置的SuspendProgram和ResumeProgram程序,明确地将节点置于或脱离省电模式。如果一个节点已经在上电或下电的过程中,该命令只会改变节点的状态,但在达到配置的ResumeTimeout或SuspendTimeout之前不会有任何影响。
对于POWER_UP,节点会经历与上面提到的类似的生命周期,只是它将处于IDLE状态,而不是MIXED或ALLOCATED状态,因为它还没有被分配到一个作业。
POWER_DOWN是由(!)符号表示的。它标志着一旦没有工作在该节点上运行,该节点就会被关闭。如果当节点正在运行其他作业时,有更多的作业被安排到该节点上,那么关闭电源可能会被推迟。一旦该节点上的所有作业完成,该节点将进入POWERING_DOWN(%)。
POWER_DOWN_ASAP将节点的状态设置为DRAINING,并将其标记为POWER_DOWN状态,以便关闭电源。DRAINING允许当前运行的作业完成,但不会有额外的作业被分配给它。当作业完成后,节点将移动到POWERING_DOWN(%)。
POWER_DOWN_FORCE取消了节点上的所有作业,并立即暂停节点,将节点置于IDLE和POWER_DOWN(!)状态,然后进入POWERING_DOWN(%)状态。
scontrol update nodename=c1-compute-0-0 state=power_down_asap
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
debug* up infinite 1 drng! c1-compute-0-0
debug* up infinite 99 idle~ c1-compute-0-[1-99]
¶ 节点特性插件和云节点
由NodeFeaturesPlugins定义并附加到slurm.conf中的云节点的功能,在节点断电时将是可用的,但不是活动的。如果一个作业请求NodeFeaturesPlugins的功能,控制器将分配已断电并具有可用功能的节点。在分配时,这些功能将被激活。云节点将保持激活的功能,直到节点断电(即在节点断电之前,节点不能重启以获得其他功能)。当节点断电时,活动的NodeFeaturesPlugins功能被清除。任何非NodeFeaturesPlugins的特性默认是激活的,可以作为标签使用。
例子:
slurm.conf:
NodeFeaturesPlugins=node_features/helpers
NodeName=cloud[1-5] ... State=CLOUD Feature=f1,f2,l1
NodeName=cloud[6-10] ... State=CLOUD Feature=f3,f4,l2
helpers.conf:
NodeName=cloud[1-5] Feature=f1,f2 Helper=/bin/true
NodeName=cloud[6-10] Feature=f3,f4 Helper=/bin/true
特性f1、f2、f3和f4是可改变的特性,并在slurm.conf中的节点行中定义,因为CLOUD节点在被分配之前没有注册。通过将Helper脚本设置为/bin/true,slurmd的将不会向控制器报告任何活动特性,控制器将管理所有活动特性。如果Helper被设置为报告活动特性的脚本,控制器将验证报告的活动特性是控制器中节点活动可改变特性的超级集合。特征l1和l2将永远是活动的,可以作为可选择的标签。